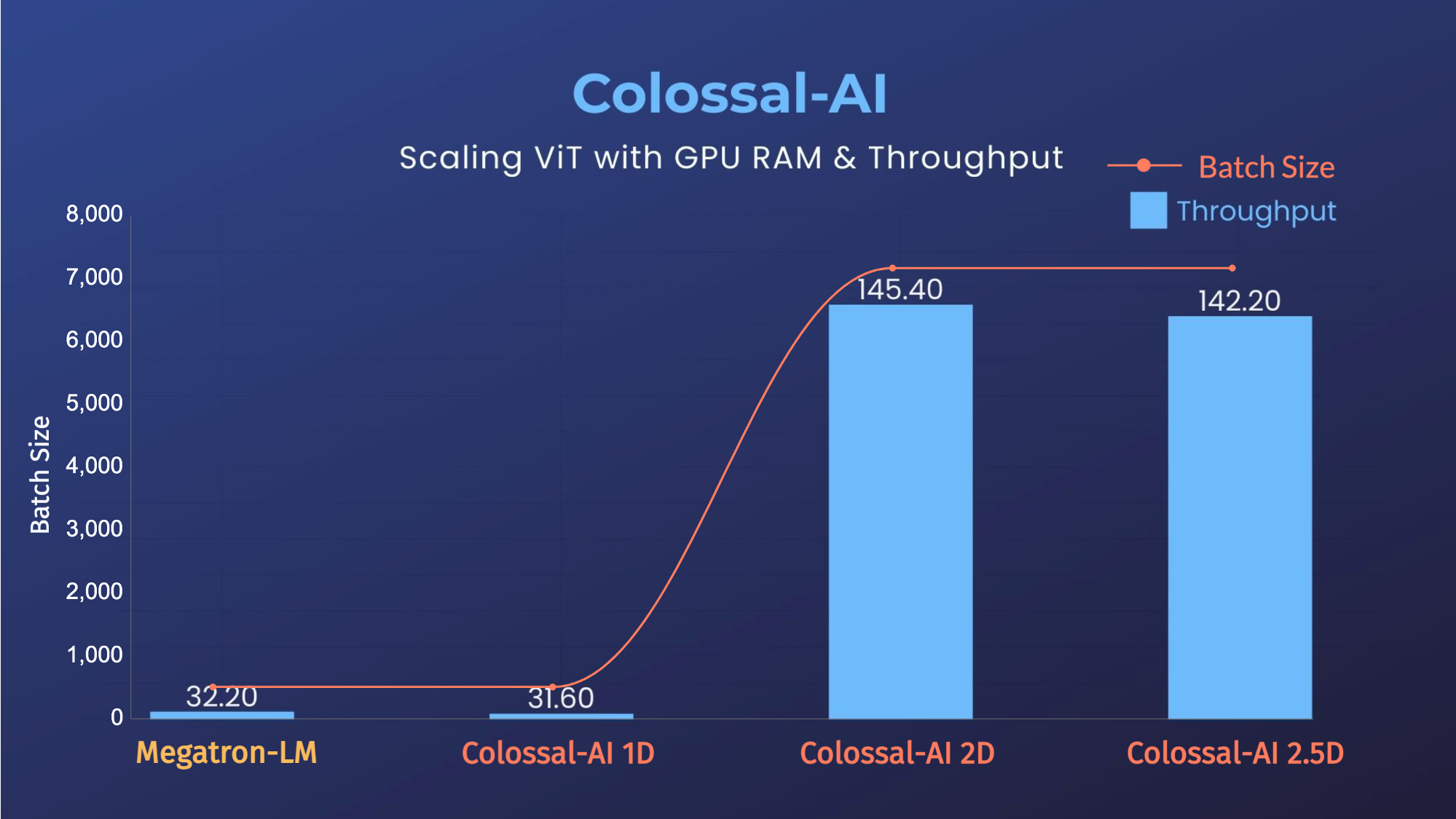
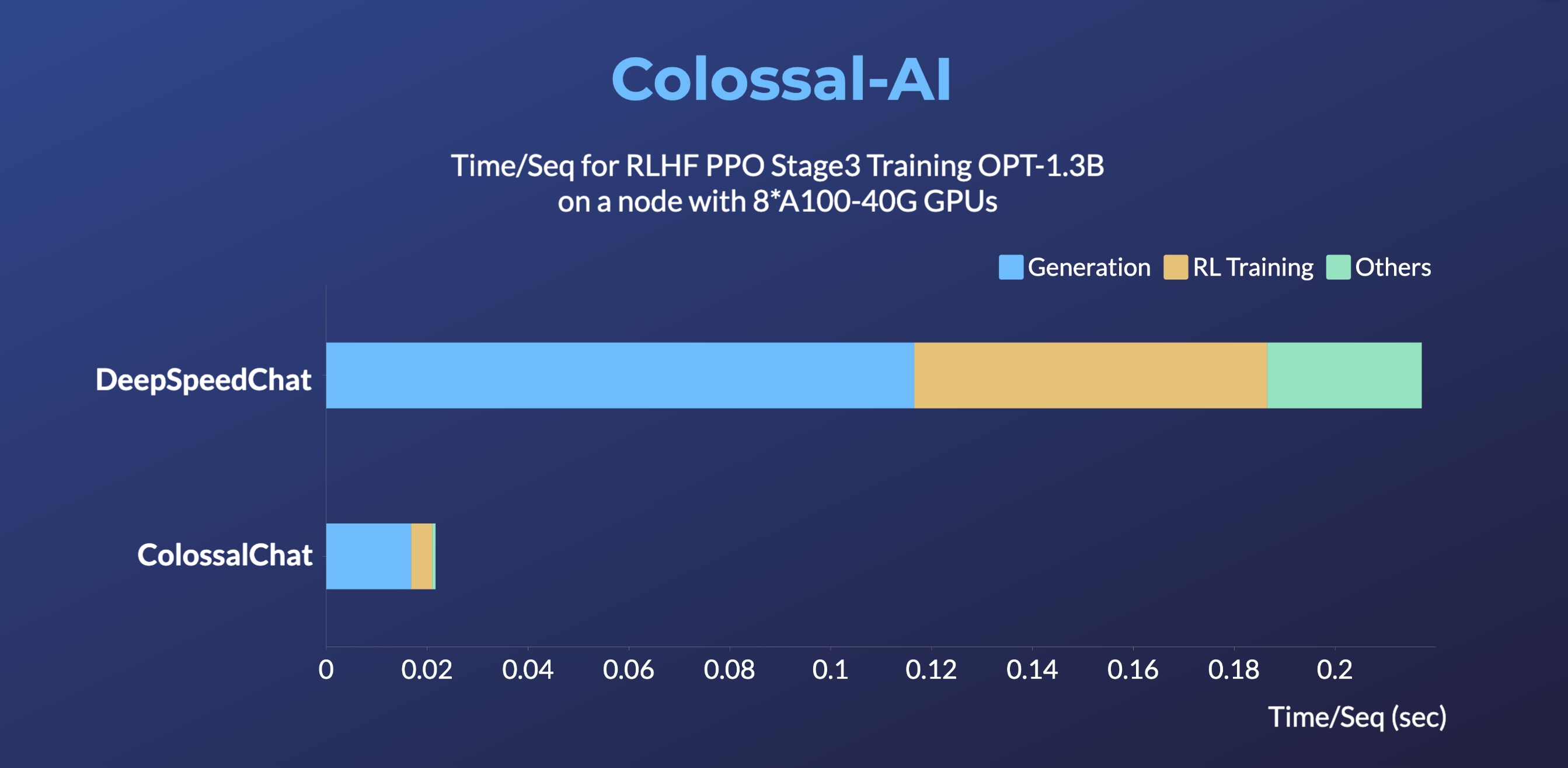
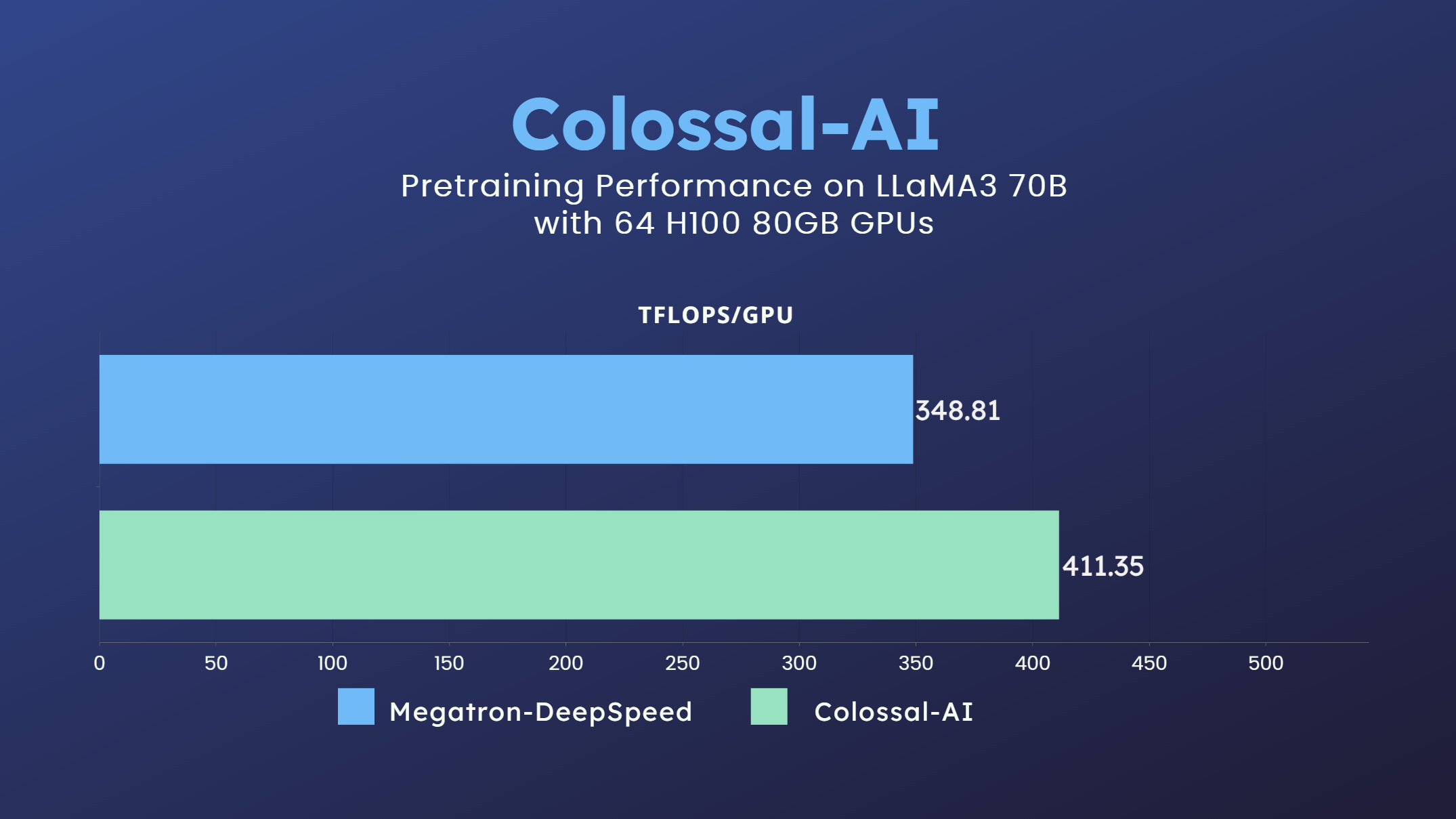
Unmatched
Speed
and
Scale
Learn about the distributed techniques of Colossal-AI to maximize the runtime performance of your large neural networks.